
三分天下,分久必合: IBM 的 Kubernetes on Mesos 探索之路
dataman · 2016-11-10 15:09:08 +08:00 · 3695 次点击这是一个创建于 2969 天前的主题,其中的信息可能已经有所发展或是发生改变。
今天是数人云容器三国演义 Meetup 嘉宾演讲实录第四弹。说完了各家容器技术的实战,那么最后来看容器技术的融合—— IBM 正在探索的一条道路。
我叫马达,名字很好记,挂的 title 是 IBM 软件架构师,但我更喜欢下面这个角色: kube-mesos 社区负责人;我在 Mesos 和 Kubernetes 两个社区都有不同的贡献。国内我是较早一批进入 Mesos 社区的, 2014 年开始通过 meetup 认识了很多技术圈的朋友,后来由于公司的需要就转到了 Kubernetes ,目前在 team 里主要做的是 Kubernetes on Mesos 。
很多人对 Kuberneteson Mesos 有疑问,说这两个东西放在一起到底有没有价值。前段时间有人在微信群里问我是不是为了集成而集成,搞一个噱头,大家一起去玩这个事情。这方面我会讲一下,以及 Kuberneteson Mesos 现在已经有将近一年没有人维护了,所以现在我们接手以后有很多事情要做,包括后面的很多功能要完善。
kube-mesos 历史
Kubernetes on Mesos ,现在我一般是叫 kube-mesos 。 Kubernetes on Mesos 这个项目最早从 2014 年开始,从 Kubernetes 刚开始的时候, Mesosphere 就投入精力把它们做一个集成。后来 Mesosphere 出了自己的 DC/OS ,就不再投入资源了。 2015 年的时候版本跟得很紧,从 0.3 一直到 0.7 十几个 release ,到了 2016 年最后一个版本 release 是 0.7.2 ,到今年的 1 月份就很少 release 了。 9 月, IBM 开始接手,因为 IBM 整个产品都是基于这个 Kuberneteson Mesos 为基础的。这时 IBM 把它重新定义成一个孵化器的项目,把它从 Kubernetes Github 里面拆出来,放到 Kubernetes 孵化项目里面。

9 月,当我们跑 Kuberneteson Mesos 这个项目的时候也是得到了很大的支持,现在的 Sponsor 是 Google 的 Tim ,他主要会帮我们一起去 review Kubernetes on Mesos 后面的 roadmap ,以及什么时候升级为 Kuberentes 的顶级项目。现在有一个叫 Champion 的角色类, Champion 这个角色来自红帽的 David ,他会和我们做一些 daily 的 review ,看一下 process 和一些 BUG 。这是我们现在在 Github 上的一个 ID ,所以现在我主要负责 Kubernetes 后面的一些 roadmap ,也希望大家一起去共享这个项目,因为后面有很多非常有意思的项目,不仅要改 Kuberntes 、 Mesos ,还有我们一些新的想法。下面是 Github 的地址 ( https://github.com/kubernetes-incubator/kube-mesos-framework/ ),到 Github 可以找到相关的资料。
为什么 kube-mesos ?
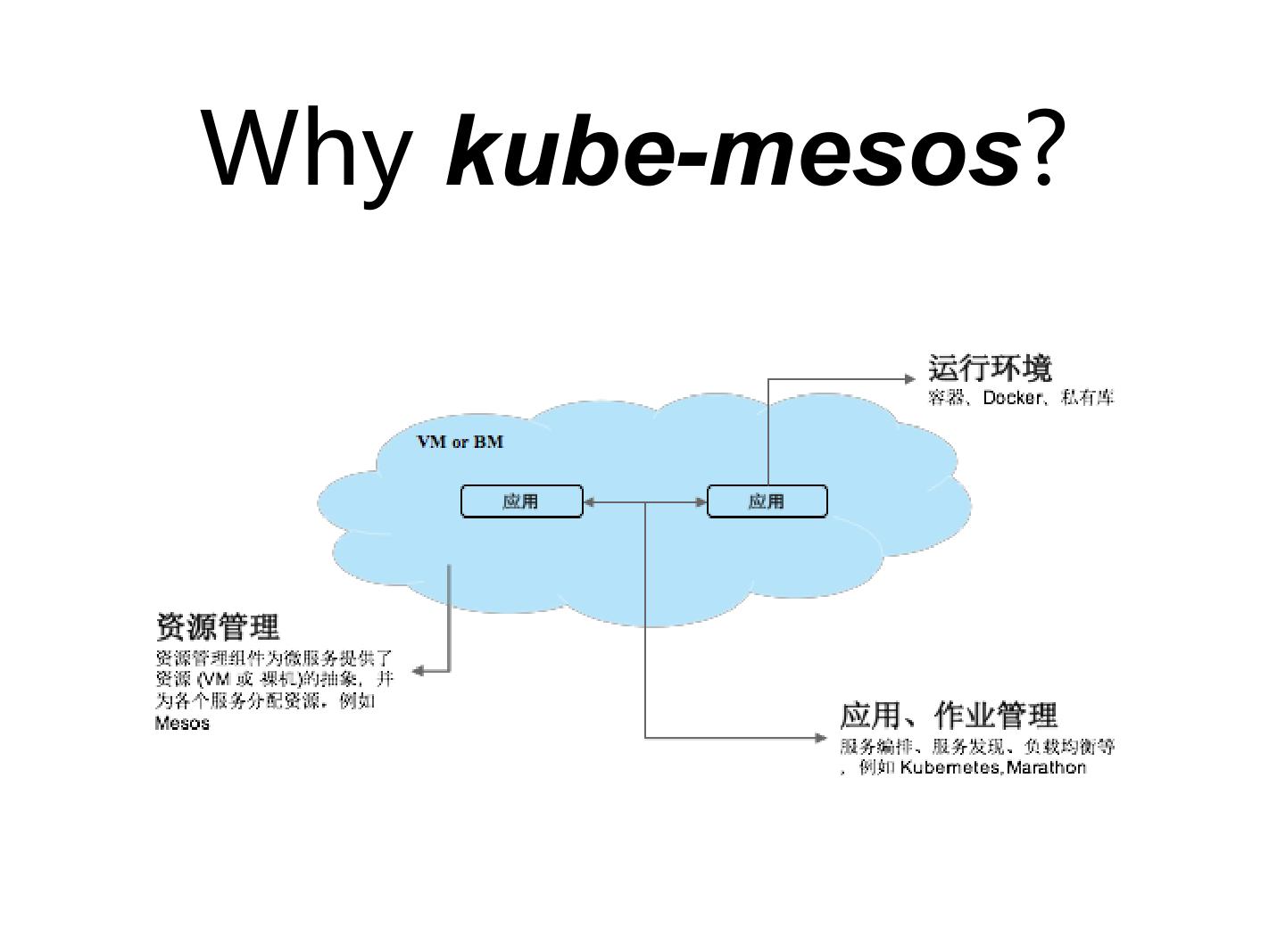
为什么要做这样一个项目,把两个社区或者两个比较复杂的东西放在一起。大家看一个环境的时候,现在讨论最多的是容器,但真正到一个数据中心或者企业环境,你会发现其中会有各种各样的 workload , Kubernetes on Mesos 只是其中的一部分。在作业管理和应用管理这一层的话,比如跑大数据会希望用 Spark ;跑管理容器相关的时候,可以跑一些 Kubernetes 、 Marathon 这样的功能。但这时候是分开的,不同的 workload 使用不同的框架。再往下一层的时候,这些 workload ,是可以把资源共享、可以把资源重新抽象出来。
这就是 Mesos 最开始提的事情,把资源重新抽象出来,抽象出一个资源池,有 CPU 、有 memory 。这也是为什么 Mesos 在描述自己的时候,它会说抽象出一个资源池,在 Google 的 Omega 文章里面,它也会提把 Mesos 定义为第二代调度的策略,两级的调度出来 scheduling 。 Omega 这个事, Google 还没有实现,所以现在也无人提。
真正说容器、说 Docker 的时候,最早它只是一个运行环境,每一台机器上一个 Docker agent ,然后把机器提起来,负责一些起停监控等。我们把资源管理用 Mesos 抽象出来,上层的应用管理可以放 Kubernetes ,也可以放 Marathon 、 Spark 。一些用户已经搭建了环境,底层是 Mesos ,上面的容器化是跑 Kubernetes ,大数据跑 Spark 。 Hadoop 那些的话,我们当时是在测试 Myriad 项目的一些功能,有许多问题和经验,有机会可以聊一下。
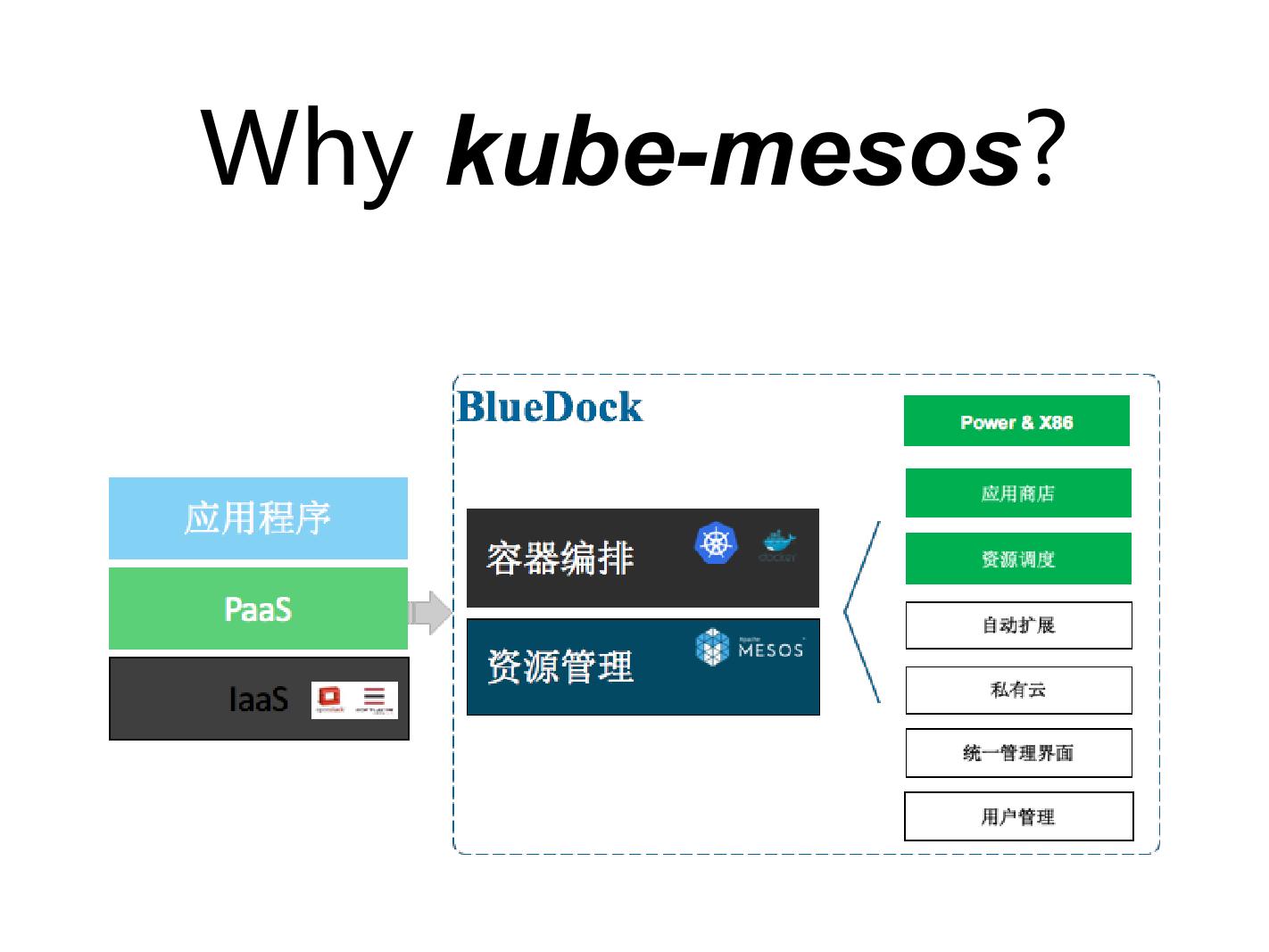
容器基本都在 PaaS 这一层, IaaS 那一层 Openstack 搞定所有的事情。 Paas 这一层抽象出来,就是是 Mesos 上面加 Kubernetes ,包括上面真正的运行环境加 Docker 。各个厂商当你做一个完整的 solution ,统一用户的管理、统一的界面,都是差不多的。做整个流程时,你不希望用户还去在意下面是跑 Mesos 还是 Kubernetes ,于是对外最后就把它抽象成业务的一个逻辑和一个业务的描述。
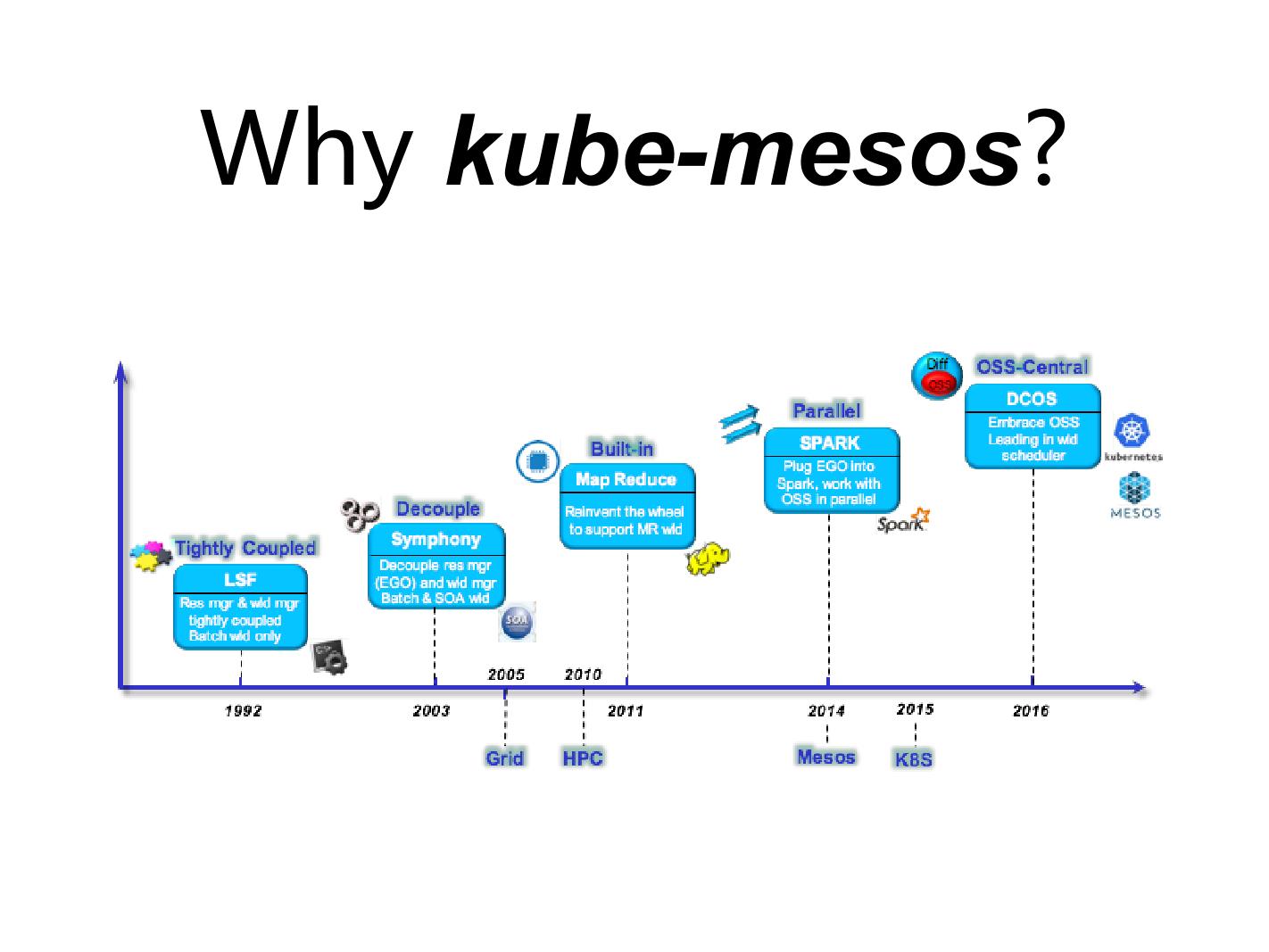
IBM 从 1992 年的时候开始做自己的产品叫 LSF ,就是说在九几年的时候像 PDS 、 SGE ,早期的 HPC, 网络计算基本上都属于这一期的。大家都比较像, workload 的管理和资源管理都放在一起了。但等到 2003 年的时候,资源管理那一层, IBM 在做新产品的时候资源管理层又做了一遍,而且是有这样的需求,一些大的银行用户里面 LSF 和 Symphony 两个是需要同时跑在一起的,而且由于它们业务上的问题,白天的时候大部分资源给 Symphony 这个产品,晚上的时候有一部分资源要给 LSF ,即另外一个产品。
中间资源的切换,如果是原来的话,只能去写脚本,把这个 cluster 一些 agent 重新提起来放在那边,但是下面如果把这个资源这层重新抽象出来的话,我们内部产品叫 EGO ,其实跟 Mesos 非常像,这也是为什么 IBM 在 Mesos 有很大的投入。包括我们这边有很多高级调度策略,像刚才说按时间的调度,包括一些资源的分配和资源的共享。
从 2003 年的时候, IBM 就开始做这样相应的事情,资源管理是一层,上面的 workload pattern 是一层。放眼整个开源社区,我们发现 Kubernetes 对容器的管理这一方面做得更好一点,所以最后选的还是 Kuberneteson Mesos 整体的架构。当 2006 年我们在做 DCOS 类似 Paas 平台这样一个产品的时候,最终定出来的方案就是说 Kubernetes on Mesos 。可以看到整个产品的架构从零几年开始做,而且基本验证了至少现在是一个正确的方向。
待解决问题

Kuberneteson Mesos 现在将近有一年没有再发布新的版本了,目前有很多问题。第一个, Kubernetes on Mesos 这个项目到年底、明年年初最主要做这个项目就是要把整个 refactor 一下,最主要的原因是现在的 Kuberneteson Mesos 对 Kubernetes 的代码依赖非常严重。它集成的时候是把 Kubernetes 里面很多组件拿过来,在外面再包一下,它是代码级别的改造。我在 9 月份刚开始接受那个项目的时候,经常会有 Kubernetes 主干的人告诉我,我们这块有 interface 变了,你要赶紧去看一下,要不然可能就编译不过,问题是它的改动基本都是内部的 interface ,其实对我外部的像 RESTful API 这些东西是不需要变的。所以在这块最主要做的是要把它分离出来,跟 Mesos 、 Kubernetes 集成的这些 interface 和这些接口,我们都希望通过它的 RESTful API 来做。
这部分还有一个更大的 topic , 11 月份的 KubeCon 与 Google 在讨论这个事情, Google 前两天也有人在做——希望 Kubernetes 可以提供一种资源管理的功能,无论是它本身提供还是它提供资源管理这一层,希望 Spark 可以利用这样的一个功能,而不是说 Spark 再去写,希望做这样的集成。我们也是希望 Kubernetes 可以更友好的去支持资源管理这一层。基于之前的那些经验,我们会在社区里推动它,至少它对 resource manager 的支持,不仅仅是对 Mesos 的支持。因为我知道 Horon work 也在做 Kubernetes on Yarn ,就是说这个 Yarn 也是资源管理这一层, Yarn 、 Mesos 包括我们内部的一些资源管理 EGO, 很多都是属于空层这一层,所以 Kubernetes 把它定位成一个 container 管理的软件,下面是可以把它完全抽象出来,让它更好的接受资源管理这个东西。
就代码级别来看的话,其实 Swarm 对资源管理层支持得更好,因为它默认自己是需要有资源管理这一层的,它把自身 Swarm 和内部这个调度都重新写成了一个 resources manager 资源管理。虽然它没有 Mesos 强,但是跟 Mesos 是一样的,所以它很容易就接到 Mesos 里面去。但 Kubernetes 现在是不用做这样的事情,它把整个全都揉到一起,所以这在后续的 KuberCon ,我们也需要更多人去讨论,是希望它能把这个东西得抽象出来,而不是说我们自己再去搞这样的东西。
revocable resources 在 Mesos 里面基本上是资源的借入借出。现在的 revocable resources , Mesos 只支持超频( Oversubscription ),这个功能现在只是超频这个部分,但现在在跟 Mesos 的社区讨论的时候,我们希望做这种资源的共享和资源的抢占。所谓资源的共享,举一个例子,我们在跟用户去做大数据和 long running service 两个同时在跑的一个环境里面的时候,对于大数据的机器是预留下来的, Mesos 里面用它的动态预留或者静态预留,应该是这部分的机器留在那儿了,因为这部分机器是相对来说比较好的,无论是网络还是存储。大数据跑起来经常会有一些数据的迁移,所以它的网络经常会被压得比较满,再把一些优先级别比较高的应用放在上面网络性能会比较差一点。但大数据的 workload 又不是时时的占满,经常会有一些空闲,所以也希望它预留下来的这一部分是可以借出去,借给 Kubernetes 一部分, Kubernetes 在上面可以跑,比如跑一些测试,一些 build ,就跑这些其实优先级并没有那么高的应用,那么从大数据的资源池借来部分 resource 基本就变成了 revocable resources 。
但是现在 Kubernetes 并不支持这件事情,它并没有去描述哪些作业是可以跑在上面、哪些是不能跑在上面。因为借来这个 resource 也会被高优先级的资源抢占掉,有可能是被杀掉,所以像一些数据库、一些比较重要的 Service 是不能跑在上面的,因为你会跑一些低优先级的作业,这样只是说有更多的资源可以用。
当上面去跑两个 framework 的时候,你跑 Kubernetes 和 Spark ,你会发现它俩之间是需要互相访问一些数据的,有的时候是运行结果,有一些是中间的数据。我们希望可以用地址去寻址,但是 Kubernetes 的 DNS 基本上在 Spark 里面又可以跑,所以你这个时候最希望的是什么? Kubernetes 的 DNS 跟 Web 的 DNS 可以通了,可以互相访问。这不光是 DNS 的事情,包括下面 Spark 的作业,因为我们在做 propose 的时候, Spark 其实跑在 Mesos 上了,无论你的 Spark master 是通过 Kubernetes 把它拉起来还是自己手动提起来,至少作业的那部分是重头,作业是希望它们可以互相访问的,所以除了 DNS 可以互通,底层的 network 也是需要互通的。
与 Mesos 集成这部分是跟 resource 相关的,因为在 Kubernetes 里边现在有太多自己的 namespace 和 Quota 。 Mesos 还有一套,有自己的 role 和 Quota 。现在社区里面在做支持一个 framework 注册多个 role ,用多个 role 的身份注册到 Mesos 上面,还在做层级的 role ,就像一个树状结构。因为这块有一些需求是这样的,在做部门的时候, Mesos 做下层资源管理时,大部分时间你是按部门的层级下来的。现在有很多人在做了,最后就变成部门一下划线,子部门一,然后再下划线,以这种形式做成一个 role ,但是这种更多的是做成一个 tree ,而且每个树状结构彼此之间是要再做一层调度的,再做一层 DNS 的算法调度。
无论如何,现在 Mesos 还不支持那么多,但是现在 Kubernetes 自己有一套, Mesos 自己也有一套,做起来会比较麻烦,你会发现 Mesos 给你分配了,有可能 Kubernetes 限制一下,你就分不出去了;或者说 Kubernetes 你感觉可以分了,但是你到那边去又调不出来,所以这两个是需要统一的。但统一有一个问题, Kubernetes 做这件事情的时候,它并没有认为这些事情应该是需要 resourcemanager 或者 cloud provide 参与的,这个事情也是需要在社区 propose ,它的 Quota 和 namespace 需要参考下面的 resourcemanager 资源分配的那一层。
Kubernetes 在做 scheduler ,其实这只是一个特例的 case ,特例的 case 是需要有一些加强的,包括 Mesos 。 Kuberneteson Mesos , Kubernetes 本身可以有 service affinity ,包括它自己可以去选择 node selector 等等功能,但是这些信息 Mesos 是不知道的,因为 Mesos 发 offer 的时候,它只管自己的事,比如说我有两个 framework ,可能那个资源换过来以后能达到更好的效果,但 Mesos 不知道这事,所以 Mesos 这块本身需要加强, Kubernetes 需要哪些 resource , Mesos 应该知道的。分出来了以后, Kubernetes 也有一层的调度,如何来更好的做这样的事情。最终会变成 Mesos 要两层的调度:第一层, Mesos 做一层,然后资源调度尽量的分出,尽量大家都匹配好;第二层,再交给 Kubernetes 去做这样的调度。
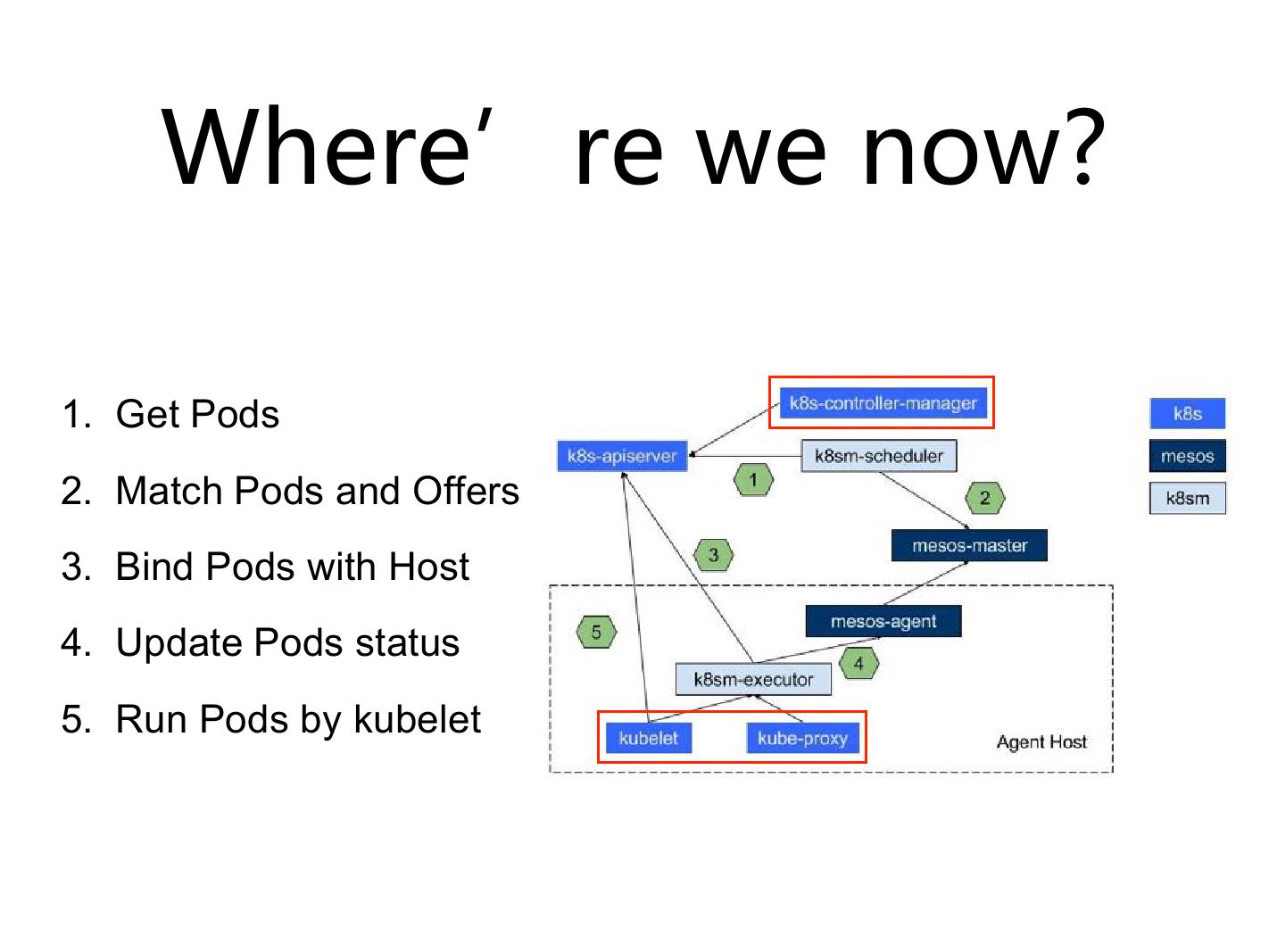
图中标红的这部分,现在去下这个包,装下来的时候,你会看到,这个东西它改了, scheduler 它改了,它还有一个 executor ,这个 executor 下面还有一个 minion 进程,然后再去起这两个子进程。而 Kubernetes 也改了,它用下面 Kubernetespackage 的包来做,不用那个 command 了,它重新改了 command 。唯一没改的就是 API 和 proxy 。但是当 refactor 以后,我们希望这两个地方都不要改了,我们真正 release 的时候只有一个 scheduler 去做这个资源的交互。只有 executor 来做这样的事情,其它的事情还是希望走它原来的逻辑来做。
这其中对 Kubernetes 本身是有一些变化的,是需要跟 Kubernetes 去做这样的事情,因为只有单独这个项目想把它做得那么流畅的话,不太现实。最主要的原因是 Kubernetes 现在自己并没有完全的去接受,并没有完全去把这个东西做成一个插件。虽然它的 scheduler 已经把它放到 plugin 里面,但它现在做得也并不是特别好。在后续的工作里面,借着子社区的建设,我们也会逐渐希望 Kubernetes 把这个底层的资源调度做得更好,而不是像现在这样所有都攒在一起。 Kubernetes 在资源管理这一层,资源管理像 Mesosresource manager 这样的一层,它如果两边都做,不见得能做得那么好。
我们现在做 Kubernetes 、做上层的时候,更在意的是它的功能。 Kubernetes 在 announce 一个新版本的时候, 1.4 去测 10 万还是几万请求压力时,它强调的一是请求不停, service 不停,它并没有强调资源的调度是否 OK 。那个只是 service 的一部分,因为如果在上面加一个 Spark 、加一个其它的大数据上的东西, Mesos 也有问题, Mesos 短作业做得特不是别好,性能有时候上不来,你需要把 scheduler inverval 调得非常低,比如调到五百毫秒以内才可以去用一用,社区也有提这个事。
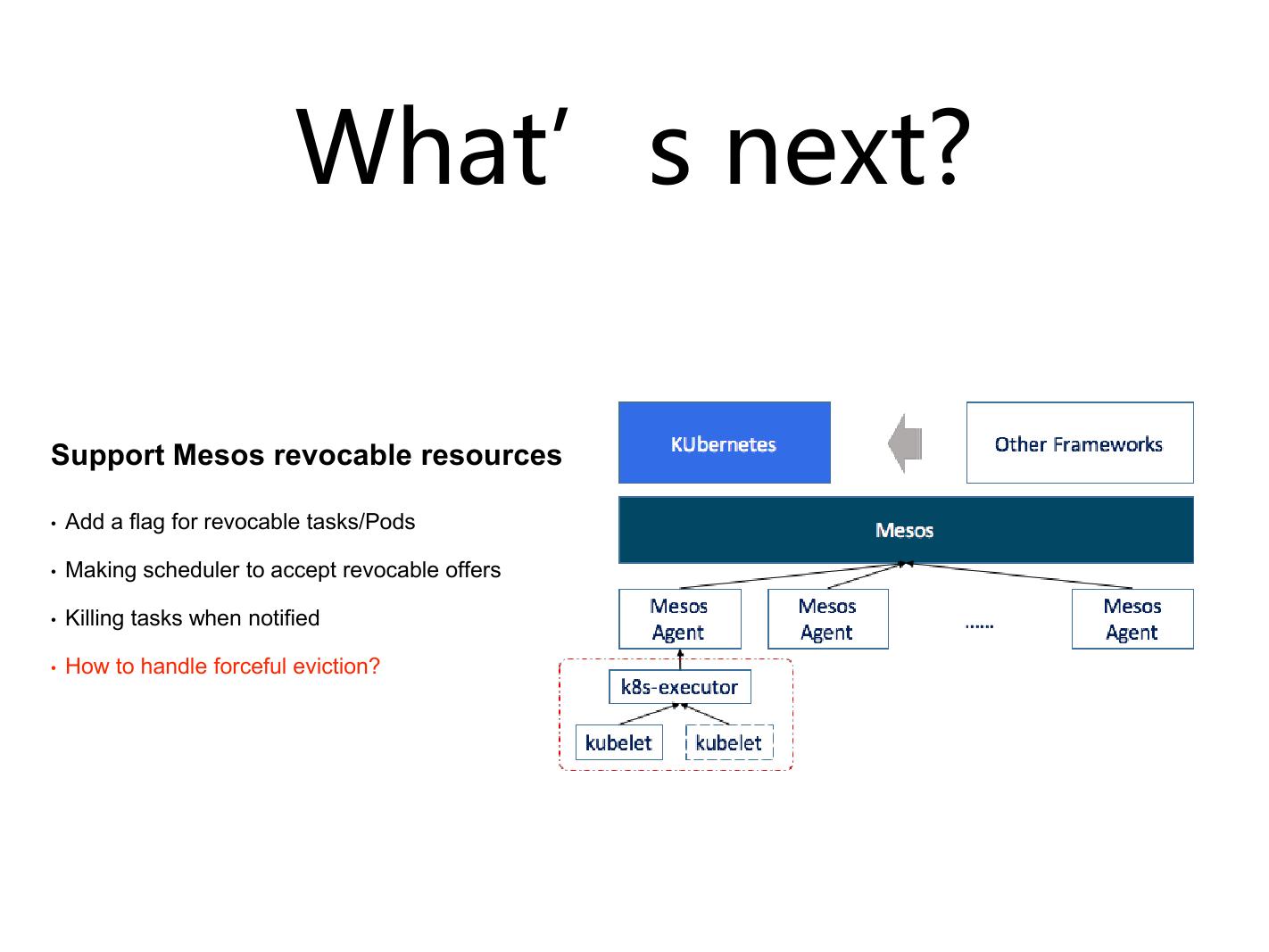
现在我们在做 revocable resource 时也有问题,比如 Kubernetes 跟其它的 framework 去交互,集成的时候 Mesos 下面走 executor ,现在所有的 Kubernetes 都在一起的,你如果去借了资源的话,你有可能 revocable resource 和 regular resource 都放在同一个 Kubernetes 上跑。但是 Mesos 为了能够完全清理所有的东西,它杀的时候直接把这东西全杀了,把 executor 下面所有的东西都杀掉了。当去杀这个 revocable resource 的时候,你会发现下面有可能顺带的把那些你不想杀的东西都杀掉了,把 regular resource 杀掉了。
现在我还没有最终的解决方案,办法之一是起两个 Kubernetes 。但是 Kubernetes 设计的时候,它希望你一个节点去起一个东西,不要起那么多。 revocable resource 这块到底该如何做大家可以一起讨论一下,因为 Mesos 有自己的一套策略, Kubernetes 也有自己的策略。我们也在跟 Mesos 社区提这个事情,要提供一个机制去杀 task ,如果 task 执行不了,再去杀 executor 。但是这个项目貌似并没有特别高的量级,我们也在想办法要么去改 Mesos 、要么去改 Kubernetes ,让它把这块做得更好。毕竟如果误杀,整个功能就没有特别大的意义了。其实作业上经常会有混合的形式。
现在 Kubernetes 有这么多 namespace ,该怎么办? Mesos 一直想做 multiple role ,从去年年底、今年年初 design document 就已经出来了,但是一直没做。它的功能是把 Kubernetes 作为一个 frameworks ,它可以 role1 、 role2 、 role3 这三个 role 注册到 Mesos 里面, Mesos 里面会根据它自己现有 DRF 相对三个 role 来分配资源。往上对应的话,有可能 role1 就对应 namespace1 , role2 就对应 amespace2 , role3 是 amespace3 ,这样跟 Kubernetes 就可能对得起来。比如它的 Quota 是管理文件这些事情,它的资源可以跟 Mesos 的 Quota ,上面这两个可以通起来的。
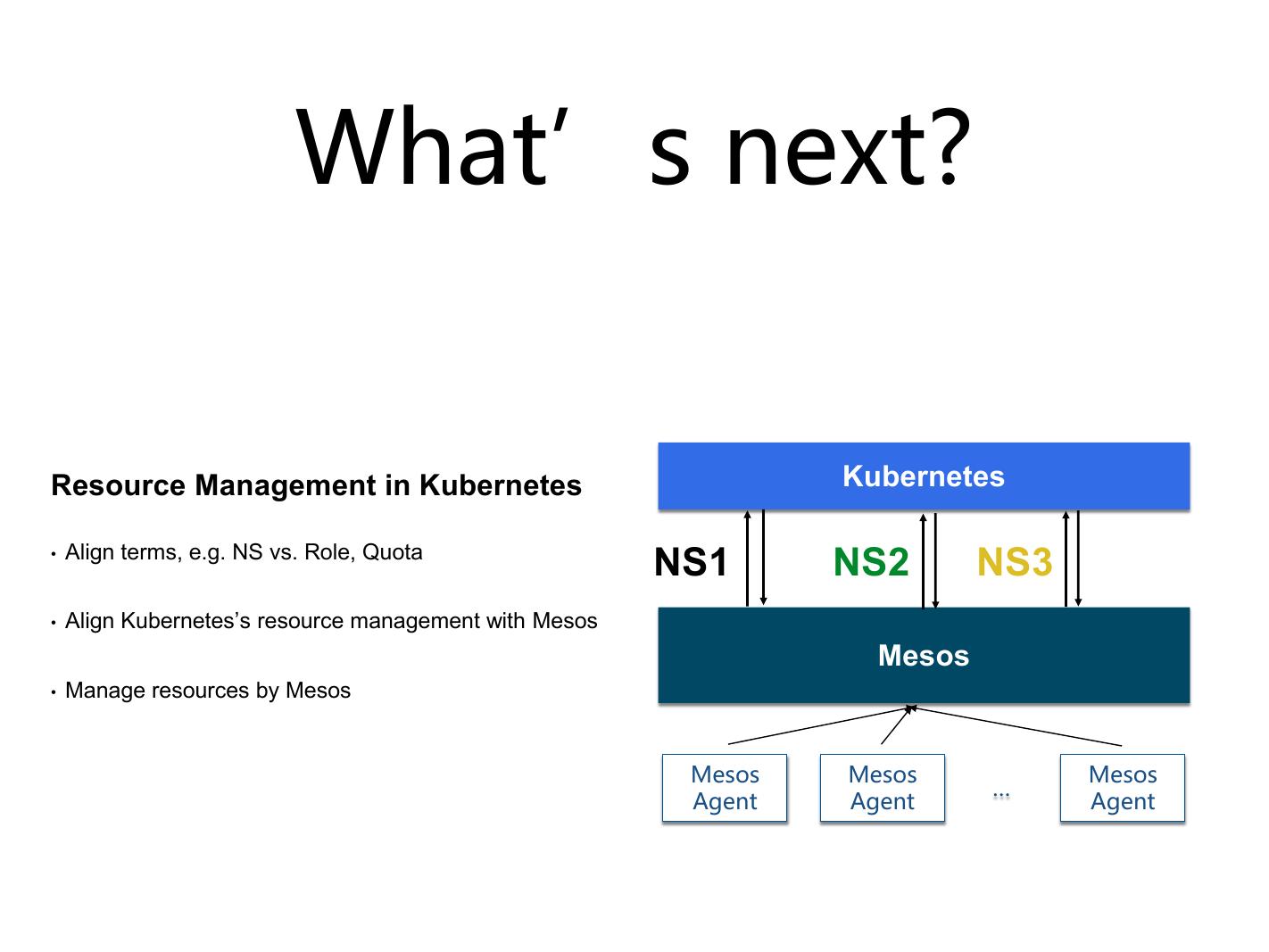
这也是我们一直在想做的事情, Mesos 和 Kuberentes 的统一资源管理,希望它把 multiplerole 做出来。最后你会发现 web interface 主要是从 Kubernetes 进来,比如创建一个 interface , Kubernetes 里面会有一个 interface ,下面底层是紧接着 Mesos 带着一个 role ,所以所有资源的管理都可以穿得起来。但是现在是变成这样了, Kubernetes 是以一个 role 分到 Mesos 上面,然后在里面自己再去做。这样其实相当于把资源管理分开了, Kubernetes 自己管一层, Mesos 自己再管一层,最好还是希望 Mesos 可以去把整个所有的资源管理都管到一块去。

后面是一些细节,一个是 scheduler enhancement ,因为一旦引入了两级调度,如果还是跟原来一样其实没有任何意义,像 K8S service 这些事情现在都做得不是很好。 Kuberneteson Mesos 里面会有很多像 like ,像 constraint ,比较像 Marathon 的一些概念在里边,这并不是一个很好的事情, Kubernetes 本身就应该有 Kubernetes 自己的东西在里面。另一个像对资源的管理和这些 Policy ,像它动态预留或者静态预留的一些资源,包括它对 Quoto 的管理,现在也是希望 Kubernetes 可以去完全支持,而不是自己再来一套。
最后,这是需要跟 Mesos 一起去 work 的,一旦有了 Service ,一旦有了 node selector ,、希望 Mesos 能够知道这件事情,然后在做调度的时候也考虑这件事情,而不是盲目的分,分完了半天不能用,再还回去,因为想用那个节点有可能别人已经用了。并不是所有人都按套路出牌,说没有这个 level 就不用了,这个事情需要 Mesos 来统一控制的。这也是为什么希望有一个资源管理层,可以控制所有的 resource 。
网络这一层,当你去架到大数据架到 longrunning framework 以后,像 DNS 、 network 连接,底层是要把它打通的。否则有很多 case 无法运行,比如一些 Spark 的数据要连到 K8S 里面,它永远是通过 K8S ingress resource 这些东西往上 push 。
kube-mesos 时间表
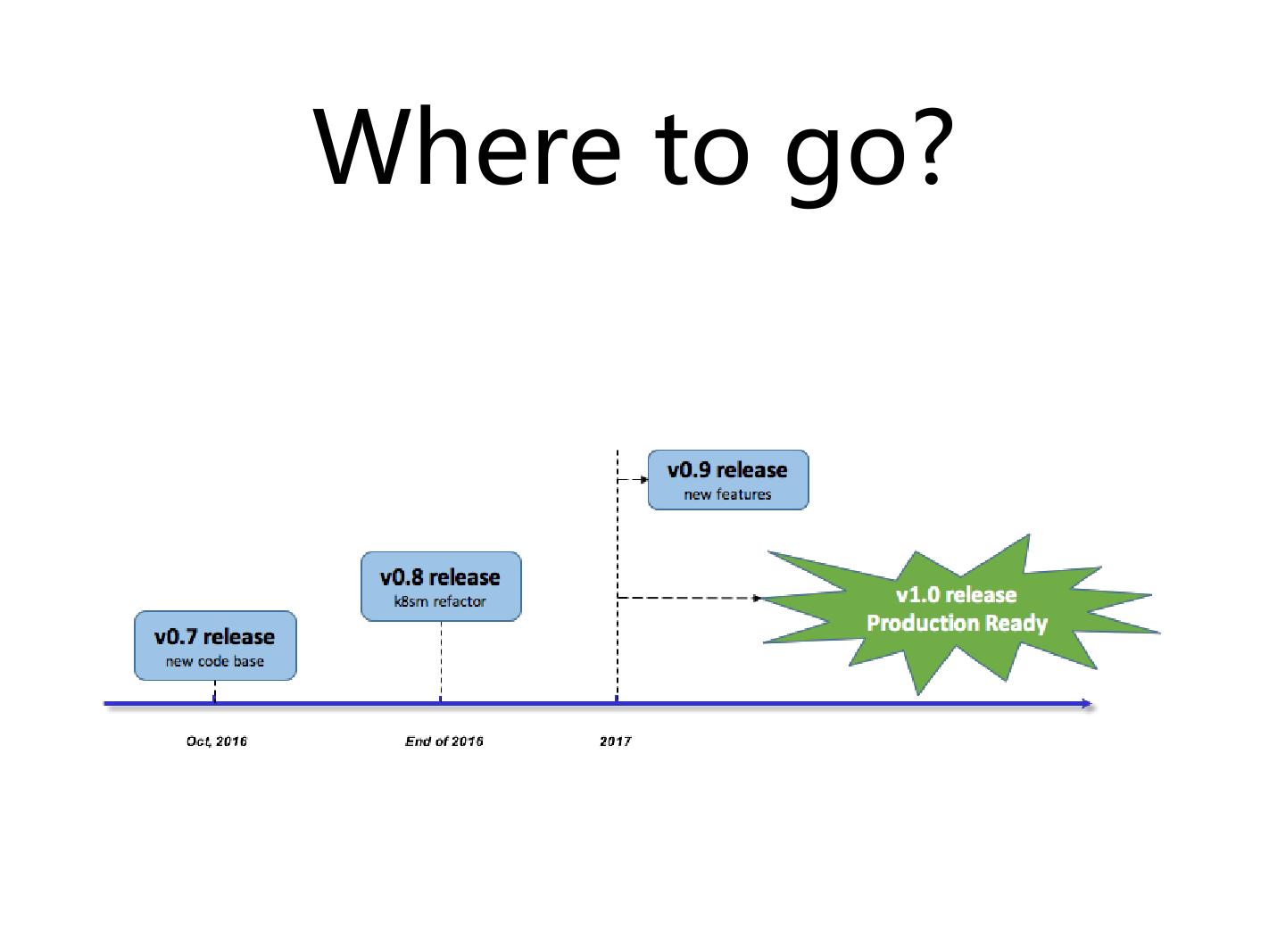
这是一个大概的时间表,在 10 月底或者 11 月初,希望 Kuberneteson Mesos 在新的 code branch 可以 release 版本,延续它之前的版本叫 0.7 。这个版本大概会留半年到一年。到 2016 年底、 2017 年初的时候,计划把 refactor 这个事情做完,我们现在最主要的事情避免这个项目对 Kubernetes 本身代码级别的依赖太强,希望通过 interface 、 API 搞定这件事情。到 2017 年的时候,刚才提到的一些主要的 feature ,像 revocable resource 以及前期的资源调度,会把它们加进去。
在 2017 年一季度应该会有一个 0.9 的 release 。在 2017 年最主要做的事情是 production , production 不是跑两个测试就是 production , IBM 有一个基于 Kubernetes on Mesos 的产品,基于产品也会做 system test ,做一种 longivity test ,大概一百台机器跑一个月,所以会以产品的形式来 release 。当它们都做完了以后,我们才会说 Kubernetes on Mesos1.0 可以上 production 。那个时候如果大家有兴趣的话可以去试一下,有很多的公司也想把两个不同的 workload 、公司内部所有的资源统一在一起,上面运行不同的 workload 。
希望大家多到社区贡献,刚开始是有很多讨论都可以把它 involve 进来,因为到后面项目比较多的时候有可能有一些 miss 。谢谢大家!
目前尚无回复